Paper Explainer: ClearPotential: Revealing Local Dark Matter in Three Dimensions
/
This is a paper explainer for my recent work with my graduate student Eric Putney, previous Rutgers postdoc (now at Institute of Basic Science in Korea), and my Rutgers colleague David Shih. This is the culmination of a series of papers, which I’ve written about here.
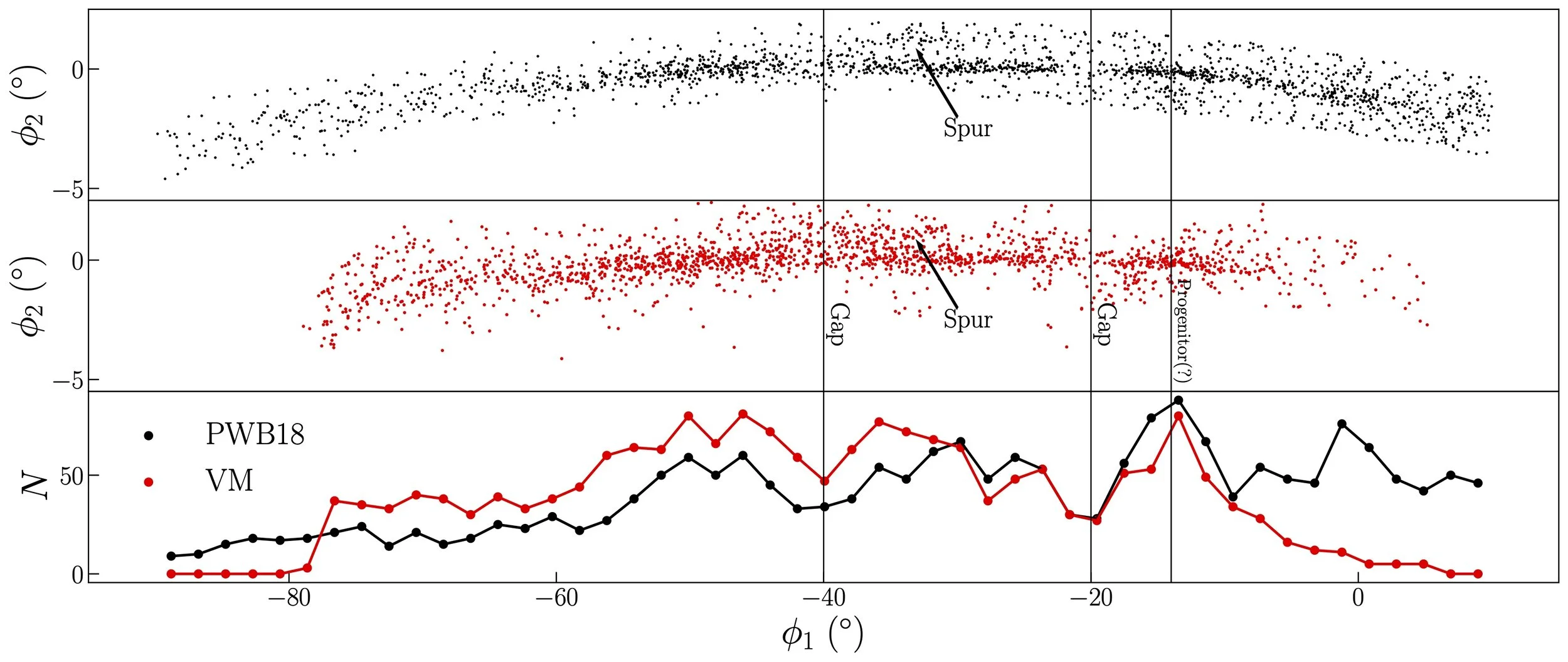
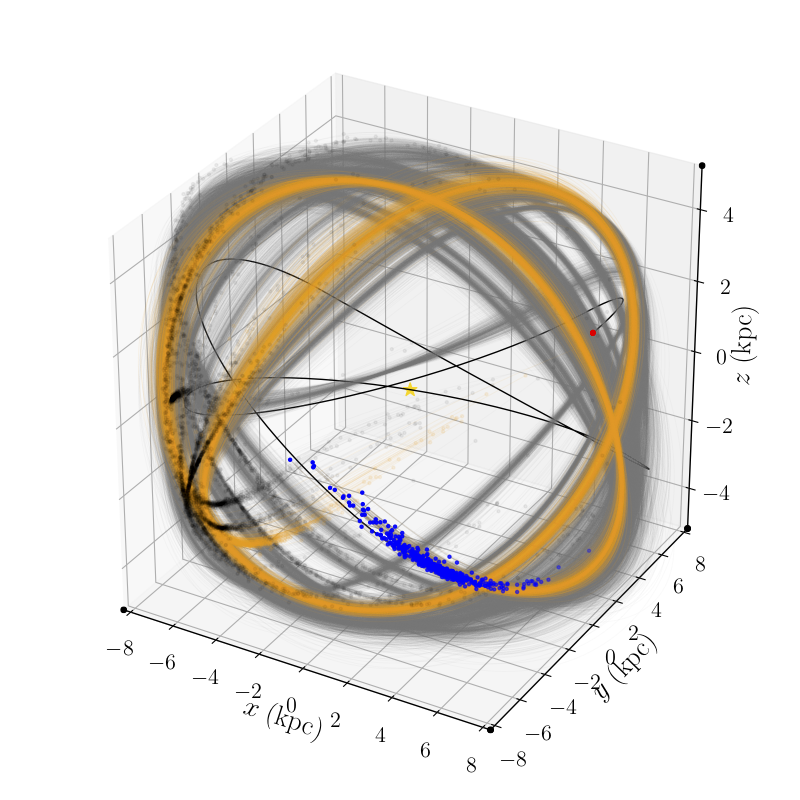
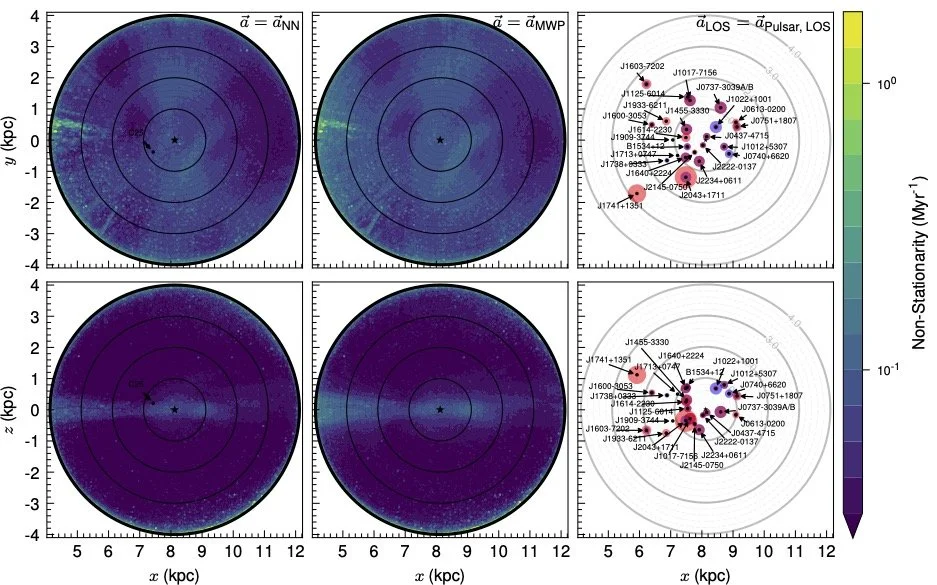
The goal of this paper and the larger project is to use the collective motion of the stars near the Earth, as measured by the Gaia Space Telescope, to measure the gravitational potential, acceleration, and mass density of the Milky Way galaxy. In particular, once we have the total mass density, we can subtract off the visible matter (that is, stars and gas, what we call “baryonic” material) to determine the density and distribution of dark matter in the Galaxy.
Read More